Two Days, Two Data Structures: Stacks, Queues, and Why O(1) vs O(n) Finally Clicked

Two Days, Two Data Structures: Stacks, Queues, and Why O(1) vs O(n) Finally Clicked
Last week, I wrote about my biggest struggle with DSA: understanding every solution but unable to solve problems independently. I called it the “recognition vs recall gap.”
A lot changed since then.
The Unexpected Speed-Up
After grinding through singly and doubly linked lists for over a week, I was nervous about stacks and queues. Would I hit another wall? Would I struggle for days like before?
I completed both in just 2 days.
Not because I’m suddenly brilliant. Not because these topics are “easier” (though they are simpler conceptually). But because I had built a foundation.
Stacks and queues are just specialized linked lists with restricted operations:
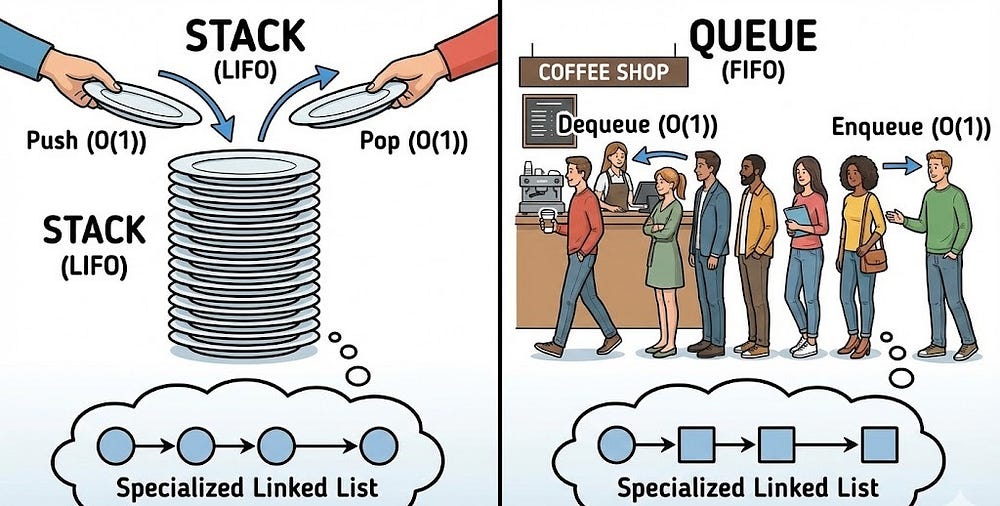
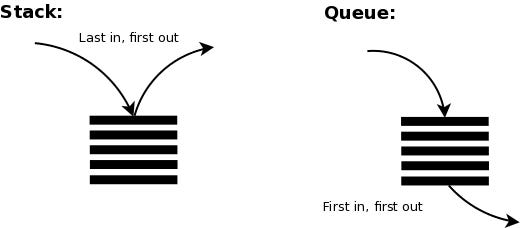
Stack: Last In, First Out (LIFO) — like a stack of plates
Queue: First In, First Out (FIFO) — like a line at a coffee shop
Once you truly understand how nodes connect and pointers work from linked lists, stacks and queues feel logical. Almost obvious.
This was my first proof that the struggle with linked lists wasn’t wasted time. It was building blocks for everything else.
Everything Seems Clear… Until LeetCode
Here’s my current reality:
Concepts? Crystal clear.
I can explain LIFO vs FIFO. I can implement a stack with push, pop, and peek. I understand queue operations — enqueue, dequeue, front, rear.

LeetCode problems? Still hard.
There’s a massive gap between understanding what a stack is and knowing when to use it to solve a problem.
Take this example: “Valid Parentheses” — given a string of brackets like “{[()]}”, determine if they’re balanced.
I know what a stack is. But recognizing “Oh, this is a stack problem!” and building the solution logic? That’s the hard part.
This is exactly what my instructor Scott meant: understanding data structures is step one. Recognizing patterns and applying them is the real skill.
When O(1) and O(n) Finally Clicked
Scott’s course covers Big O notation throughout — analyzing time and space complexity. I’d heard these terms before, but they never really clicked until now.
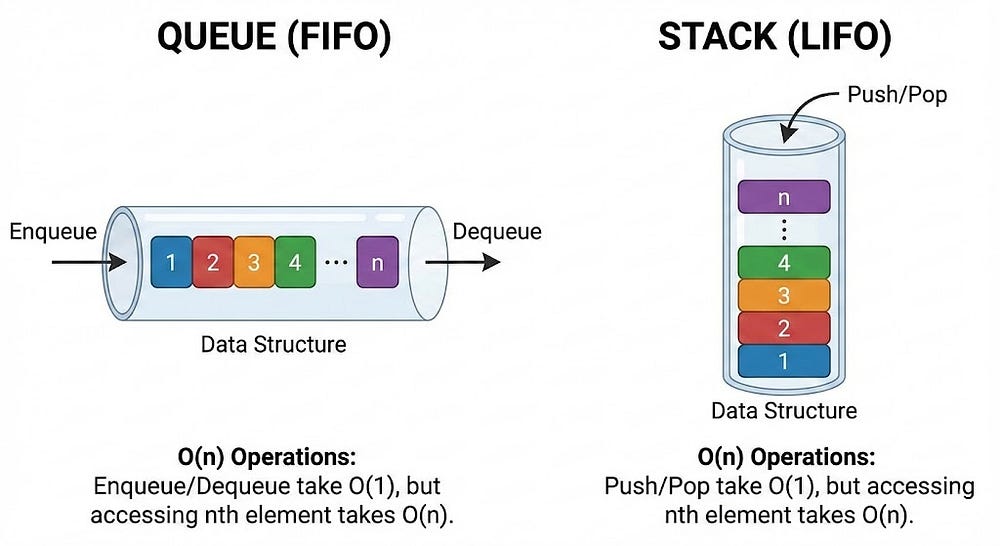
O(1) — Constant Time
Operations that take the same amount of time regardless of data size.
Stack examples:
push()- add to top → O(1)pop()- remove from top → O(1)peek()- view top element → O(1)
Why? Because you’re always accessing the top pointer. Doesn’t matter if your stack has 10 elements or 10,000 — accessing the top takes one operation.
Queue examples:
enqueue()- add to rear → O(1)dequeue()- remove from front → O(1)
Both ends are tracked with pointers, so adding/removing is instant.
O(n) — Linear Time
Operations that scale with data size.
Stack/Queue examples:
Searching for a specific value → O(n)
Printing all elements → O(n)
Why? You potentially need to visit every single element. 1,000 elements = 1,000 checks.
Why This Matters
Before understanding Big O, I’d write any solution that worked. But in interviews, efficiency matters.
A brute force solution might work for 10 elements but crash with 10,000. Knowing O(1) vs O(n) helps you:
Choose the right data structure
Optimize your approach
Explain trade-offs in interviews
Example: Need to frequently add/remove from both ends of a collection?
Array → O(n) for adding to front (must shift everything)
Doubly Linked List → O(1) for both ends (deque)
Understanding time complexity changed how I think about solutions.
What’s Next: Trees and Hash Tables
After stacks and queues, I’m moving to:

Trees — Binary trees, BST, traversals
Hash Tables — Hashing, collisions, lookups
I’m not gonna lie — I’m a bit nervous about trees. They involve recursion, which is a completely different way of thinking than the iterative loops I’ve been using.
But I also know: linked lists felt impossible at first. Now they’re my foundation. Stacks and queues felt complex, now they’re logical.
Every “hard” topic becomes the foundation for what’s next.
Current Stats
Day in journey: 11
Topics completed: Singly linked lists, doubly linked lists, stacks, queues
Daily study time: 4 hours
Confidence level: Growing, but realistic
LeetCode problems solved independently: Still working on this 😅
What I’ve Learned So Far
Foundation compounds: Struggling with linked lists made stacks/queues easy
Concepts ≠ Application: Understanding stacks doesn’t mean recognizing stack problems
Big O isn’t just theory: It changes how you evaluate solutions
Speed varies: 1 week for linked lists, 2 days for stacks/queues — both were necessary
Revision can’t wait: Spaced repetition should happen during learning, not after
If You’re on This Journey Too
Where I was wrong:
Thinking I needed to finish everything before revising. Memory doesn’t work that way.
Where I was right:
Struggling for 15 minutes before looking at solutions. Active reconstruction. Pattern focus. These are working.
What I’m adjusting:
Starting revision cycles now instead of waiting. Tracking solve rates. Being more patient with application (it takes time to recognize when to use what).
The gap between understanding and solving is still there. But it’s narrowing. Slowly. Messily. Exactly how learning is supposed to work.
Next update: after trees and hash tables. Let’s see if recursion breaks me. 🌳
Currently learning: Trees and Hash Tables
Target: Master all DSA in 2 months | Then 300+ LeetCode problems
Goal: FAANG interviews
Are you learning DSA too? What’s your current struggle? Drop a comment — let’s learn together.
— Avinash Negi
Useful Resources:
Scott Barrett’s Python DSA Course — The course I’m following
My previous article: I Understood Every LeetCode Solution But Couldn’t Solve Anything




